
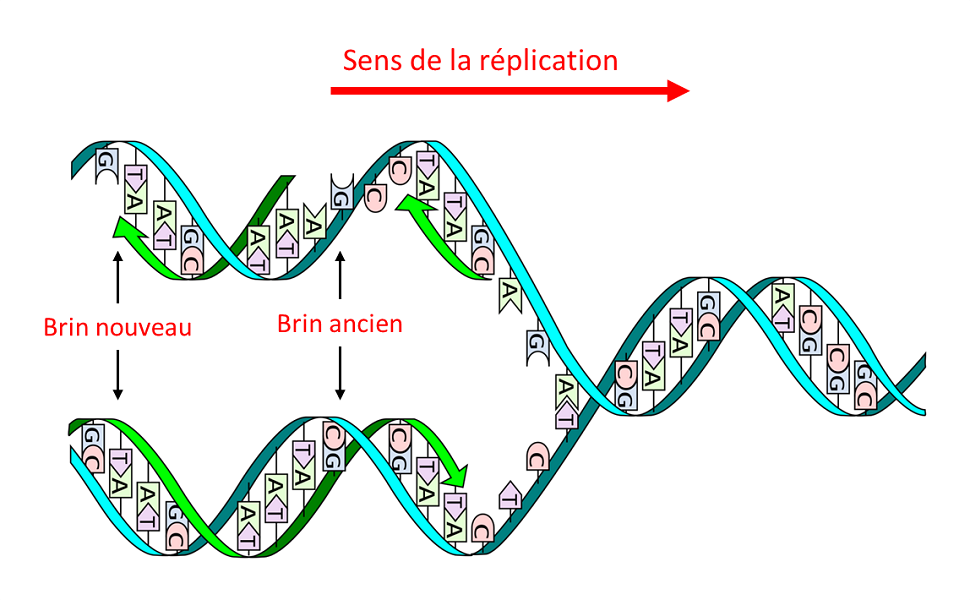
La découverte de la structure de l’ADN en 1953 a permis de comprendre comment il était recopié (on emploie également les termes répliqué ou dupliqué) lors des divisions cellulaires :
https://coronabiomol.wordpress.com/2020/07/14/ladn/
Cependant, le lien existant entre l’information contenue dans l’ADN et les protéines restait toujours incompris. Or, ce sont les protéines qui assurent la majorité des fonctions biologiques.
Protéines et acides aminés

Au cours du 19ème siècle, il apparut que les protéines se composaient d’éléments simples auxquels on donna le nom d’acides aminés. Un chimiste allemand, Emil Fischer (Prix Nobel de chimie 1902), joua un rôle déterminant dans la purification et la caractérisation d’un grand nombre d’entre eux.
Des recherches ultérieures montrèrent que les protéines de tous les êtres vivants étaient formées par l’enchaînement des vingt acides aminés présentés dans le tableau ci-dessous :
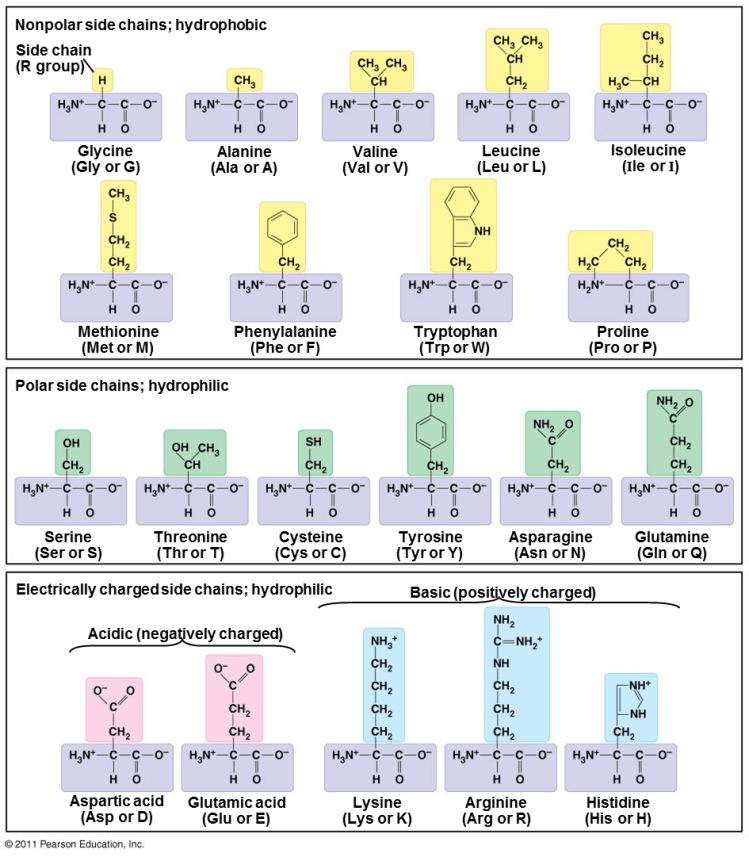
Les acides aminés possèdent à la fois un groupement acide et un groupement aminé (rectangles violets), d’où leur nom. Dans les autres rectangles (jaunes, verts, roses et bleus) sont représentés les vingt groupes latéraux qui confèrent à chaque acide aminé une propriété chimique particulière et déterminent la structure en 3D des protéines.
Les différents types de protéines comportent un nombre variable d’acides aminés dont la succession définit la séquence de la protéine.
Parmi les grands types de protéines on trouve :
Les protéines de structure (actine et myosine du muscle, collagène, kératine des ongles et des cheveux, …)
Les enzymes (Catalyseurs biologiques pour des milliers de réactions différentes)
Certaines hormones (insuline, hormone de croissance, calcitonine, prolactine, …)
Les protéines de transport (hémoglobine, transferrine, transcortine, …)
Les anticorps ou immunoglobulines
Certains antigènes, comme la protéine « spike » du CoronavirusSarsCov2
Prenons pour exemple l’insuline qui fût la première protéine à être séquencée par Sanger et ses collaborateurs (Prix Nobel 1958, 1980) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1197536/pdf/biochemj00914-0090.pdf
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1198158/pdf/biochemj00896-0041.pdf
Chaque acide aminé est représenté par trois lettres dont on trouve la correspondance dans le tableau précédent.
On peut également constater que l’insuline est constituée de deux chaînes de protéines (A et B), de séquences différentes.

Mise en évidence de relations entre ARN et protéines
Dès les années 50, plusieurs équipes de biochimistes mettent en évidence des liens étroits entre un certain type d’ARN et la synthèse des protéines.
Suite à ces travaux, il apparut qu’une partie des ARN servait de support à la synthèse des protéines et jouait le rôle d’intermédiaire avec l’ADN. D’autre part, il en ressortait que l’ARN de certains virus pouvait piloter la synthèse de protéines en l’absence d’ADN.
De ce fait, des chercheurs tels Marshall Nirenberg et Heinrich Matthaei, portèrent tous leurs efforts sur les relations entre ARN et constituants des protéines, à savoir les acides aminés.

National Institutes of Health, Bethesda, Maryland
En 1961, Marshall Nirenberg, biochimiste américain et Heinrich Matthaei, biochimiste allemand en stage dans son laboratoire, publient un article qui fait sensation dans le monde de la biologie moléculaire et constitue un tournant dans le décryptage du code génétique :
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC223178/pdf/pnas00214-0066.pdf
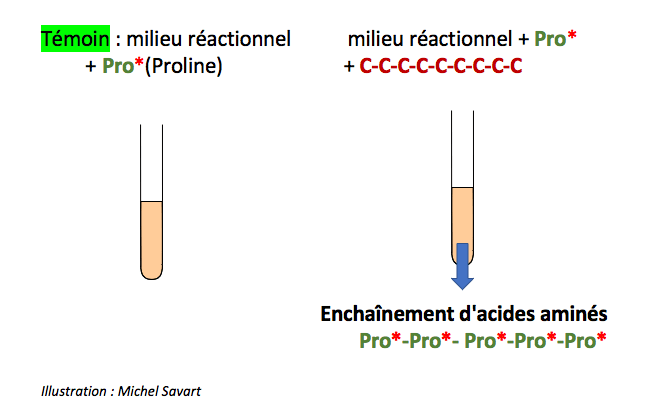
Ils ont travaillé sur des broyats de bactéries Escherichia Coli dont ils ont ôté l’ADN et auxquels ils ont rajouté un ARN de synthèse contenant une succession de bases U (U = Uracile) et des acides aminés marqués radioactivement*.
Ils testent successivement les 20 acides aminés* et constatent un enchaînement de phénylalanine* uniquement dans les tubes contenant l’enchaînement des bases U :
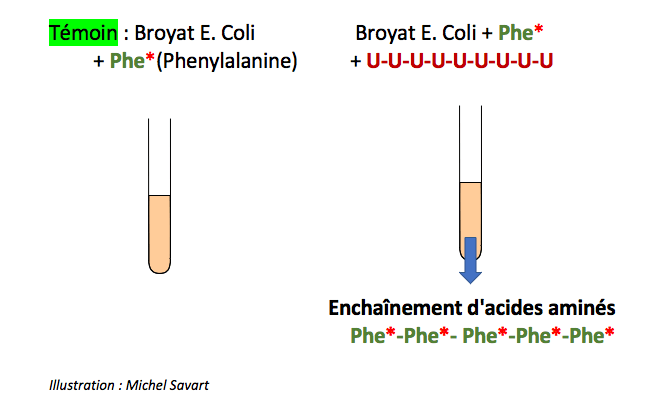
Ils viennent de créer une protéine de synthèse constituée exclusivement de phenylalanine. Ils n’observent aucun autre enchaînement avec les autres acides aminés. Ils en concluent que l’enchaînement des acides aminés Phe-Phe-Phe-Phe-Phe dépend strictement de la succession des bases U dans cet ARN de synthèse.
En 1964, ils utilisent d’autres ARN de synthèse : https://www.sciencemag.org/site/feature/data/genomes/145-3639-1399.pdf
Ils observent alors l’enchaînement d’acides aminés différents :
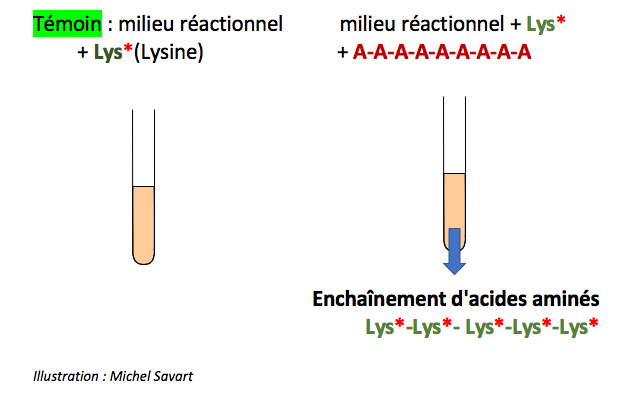
Lors de ces derniers travaux ils observent également que la succession de trois bases (triplet) dans l’ARN correspond à un seul acide aminé.
Har Gobind Khorana : un pas de plus dans le décryptage

A partir des quatre bases de l’ADN (A,T,G,C) il existe 64 possibilités de former des triplets (43 = 4 x 4 x 4). Il en est de même pour l’ARN (A,U,G,C). La seule différence étant que dans l’ARN, le T (Thymine) de l’ADN est remplacé par un U (Uracile)
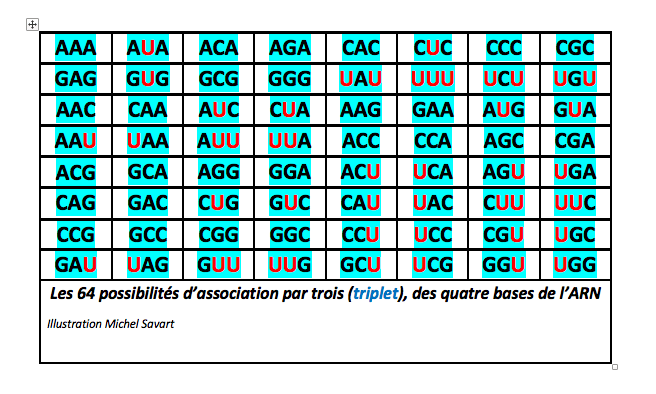
Har Gobind Khorana, un biochimiste américain originaire du Pendjab, et ses collaborateurs, mirent au point une méthode de synthèse d’ARN artificiel permettant d’enchaîner de façon très précise des triplets de bases. Ils utilisèrent ces ARN pour tester les 64 triplets possibles et étudier l’enchaînement des acides aminés correspondants.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC219908/pdf/pnas00163-0094.pdf
https://www.sciencedirect.com/science/article/abs/pii/S0022283665800985
En 1966, l’analyse des 64 triplets était terminée et aboutissait à l’élaboration du tableau qui définit le code génétique.
Le code génétique établit les correspondances entre les 64 triplets de l’ARN messager et les 20 acides aminés, pour tous les êtres vivants. Il est universel et concerne aussi bien les coronavirus que l’homme
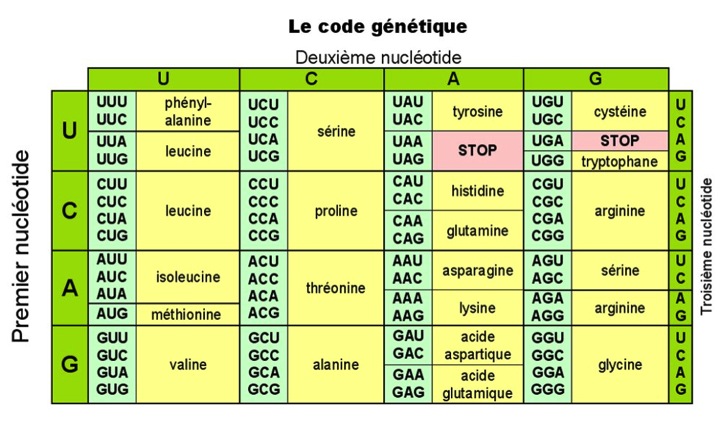
Quelques commentaires sur ce tableau
Considérons une séquence d’ARN contenant les six triplets suivants :
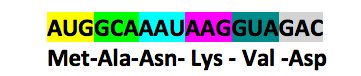
- Après lecture du tableau à trois entrées, on peut positionner sous chaque triplet les acides aminés: Méthionine (Met)-Alanine (Ala)-Asparagine (Asn)-Lysine (Lys)-Valine (Val)-Acide aspartique (Asp).
- Il faut également souligner que le code génétique est « redondant » car il existe 64 triplets de l’ARN messager pour seulement 20 acides aminés. Ainsi, plusieurs triplets peuvent correspondre à un même acide aminé.
Prenons pour exemple la sérine dans le tableau précédent : elle peut être codée par quatre triplets différents : UCU, UCC, UCA et UCG.
Cela signifie qu’en cas de mutation de la dernière base (U,C,A ou G) l’acide aminé incorporé sera toujours une sérine. On parlera alors de mutation « neutre » car il n’y aura aucune incidence sur les fonctionnalités de la protéine synthétisée.
- Si l’un des trois triplets UAA, UAG ou UGA est présent dans l’ARN l’enchaînement des acides aminés s’arrête, d’où le nom de triplet STOP. Ce signal STOP marque la fin de synthèse de la protéine.

Robert W. Holley, Marshall Nirenberg, Har Gobind Khorana, Prix Nobel 1968
En 1968, Marshall Nirenberg et Har Gobind Khorana obtinrent le prix Nobel de physiologie ou médecine « pour leur interprétation du code génétique et de sa fonction dans la synthèse des protéines ». Ils le reçurent conjointement avec Robert W. Holley dont nous détaillerons le rôle dans l’article sur l’ARN messager.
